Comprehensive Monitoring of an AWS EKS Cluster Using Prometheus, Grafana, and the EFK Stack


In this blog post, we'll walk you through the step-by-step process of deploying a sample chatbot on AWS Elastic Kubernetes Service (EKS) and setting up a comprehensive monitoring solution with Prometheus, Grafana, and the ELK stack. 🤖🔍 We'll demonstrate how users can interact with the web application and how a DevOps engineer can monitor real-time application logs.
The sample chatbot application, built using HTML, CSS, and JavaScript, will be integrated with Google Dialogflow for natural language processing. We'll deploy the chatbot on AWS EKS, a managed Kubernetes service that offers scalability and reliability. By the end of this guide, you'll have a fully functional chatbot running in a containerized environment, along with a powerful monitoring setup to ensure its optimal performance. 🌟🚀
Architecture Diagram & Github Repo
https://github.com/vikranth18devops/botapp.git

Step 1
Prerequisites
Before getting started, make sure you have an AWS account, basic knowledge of AWS, Kubernetes, EKS and the necessary permissions to create resources on AWS.
Step 2:
Creating an EKS Management Host on AWS
Before you begin, ensure that you have an AWS account, a basic understanding of AWS, Kubernetes, EKS, and the required permissions to create resources within AWS.
Launch new Ubuntu VM using AWS EC2 (t2.micro).
Connect to machine using SSH or preferred method.
2. Connect to machine and install kubectl using below commands.
curl -o kubectl https://amazon-eks.s3.us-west-2.amazonaws.com/1.19.6/2021-01-05/bin/linux/amd64/kubectl
chmod +x ./kubectl
sudo mv ./kubectl /usr/local/bin
kubectl version --short --client
3. Install AWS CLI latest version using below commands.
sudo apt install unzip
cd
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install
aws --version
4. Install eksctl using below commands.
curl --silent --location "https://github.com/weaveworks/eksctl/releases/latest/download/eksctl_$(uname -s)_amd64.tar.gz" | tar xz -C /tmp
sudo mv /tmp/eksctl /usr/local/bin
eksctl version
Step - 3:
Create IAM role & attach to EKS Management Host.
Create New Role using IAM service ( Select Usecase - ec2 )
Add below permissions for the role
IAM - fullaccess
VPC - fullaccess
EC2 - fullaccess
CloudFomration - fullaccess
Administrator - acces
Enter Role Name (eksroleec2)Attach created role to EKS Management Host (Select EC2 => Click on Security => Modify IAM Role => attach IAM role we have created).
Step - 4 :
Create EKS Cluster using eksctl.
Syntax:
eksctl create cluster --name cluster-name
--region region-name
--node-type instance-type
--nodes-min 2
--nodes-max 2 \ --zones
eksctl create cluster--name bot-cluster4 --region us-east-1 --node-type t2.medium --zones us-east-1a,us-east-1b
Choose your preferred name and region.Here I used name as bot and N.Virgina region.
Note:The cluster setup will take around 5–10 mins.After done with the setup.We can check the nodes status using below command.
kubectl get nodes
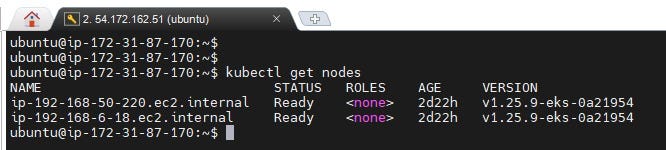
We cannot see the control plane here, as it is managed by the Elastic Kubernetes Service (EKS).
Once the setup is complete, you will see the console displayed like this:
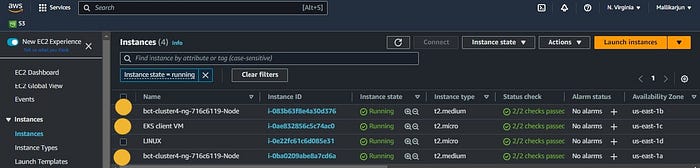
Now in console we can see that EKS client VM in order to communicate with Control plane and also we can see the two worker nodes up and running.
Deploying the Sample Bot Application
I have deployed a sample bot application using yaml file that leverages HTML, CSS, JavaScript, and Google Dialogflow. To ensure efficient resource monitoring and performance analysis, Prometheus and Grafana have been implemented to monitor the cluster resources and gather valuable insights.
apiVersion: apps/v1
kind: Deployment
metadata:
name: bot
spec:
selector:
matchLabels:
app: bot
replicas: 3
template:
metadata:
labels:
app: bot
spec:
containers:
- name: bot-app
image: vikranthdevops18/botapp:latest
imagePullPolicy: Always # Force pull the latest image
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: bot-service
spec:
type: LoadBalancer
selector:
app: bot
ports:
- protocol: TCP
port: 8080
targetPort: 80
nodePort: 32080
The provided above YAML configuration represents a Kubernetes Deployment and Service for the sample bot application. It deploys two replicas of the bot application and exposes it externally through a LoadBalancer Service on port 8080.

Access the application through loadbalancer url
af07c2eae913e4f28a275d33ec10f0a8-1581982861..
Step 5:
Setting up Prometheus and Garafana using Helm charts.
To set up Prometheus and Grafana, we will utilize Helm, a Kubernetes package manager that simplifies the installation of various Kubernetes plugins. Helm provides predefined configurations called Helm charts, which streamline the deployment process and minimize the potential for human error. Instead of manually creating multiple services and files in the correct order, Helm allows us to use a straightforward command for installation.
Helm Installation
curl -fsSl -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.sh
helm version

-> check do we have metrics server on the cluster.
kubectl top pods
kubectl top nodes
helm repo ls
# Before you can install the chart you will need to add the metrics-server repo to helm.
helm repo add metrics-server https://kubernetes-sigs.github.io/metrics-server/
# Install the chart
helm upgrade --install metrics-server metrics-server/metrics-server
After adding metric server:
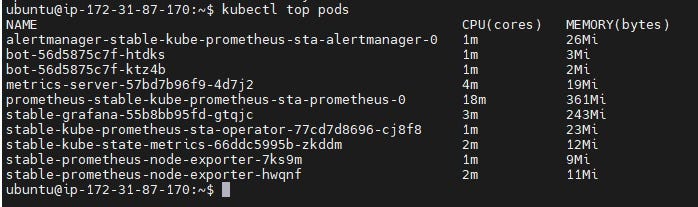

Deploy Prometheus and Grafana in a Kubernetes Cluster using HELM Charts.
To get started, follow the steps below to install Prometheus and Grafana using HELM:
- Add the latest HELM repository in Kubernetes:
helm repo add stable https://charts.helm.sh/stable
- Add the Prometheus repository to HELM:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
- Update the helm repo:
helm repo update
- Install Prometheus using the prometheus-community Helm chart:
helm install stable prometheus-community/kube-prometheus-stack
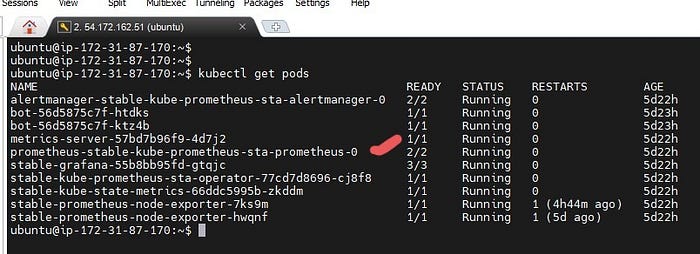
- Verify that the Prometheus pods are running:
kubectl get pods
kubectl get svc
Edit the Prometheus service and change the service type to LoadBalancer:
kubectl edit svc stable-kube-prometheus-sta-prometheusRepeat the previous step to edit the Grafana service and change the service type to LoadBalancer:
kubectl edit svc stable-grafana
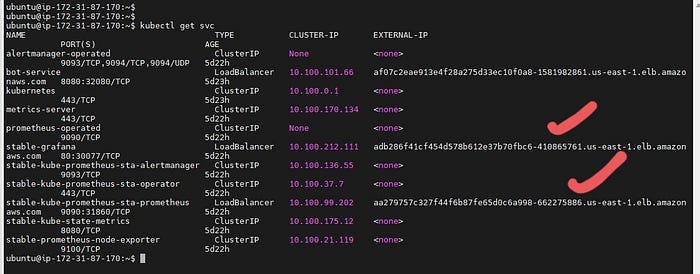
Verify that the services have changed to LoadBalancer:
kubectl get svc
Now, you can access Prometheus and Grafana using the LoadBalancer URL:
Prometheus URL: LBR-URL:9090
Grafana URL: LBR-URL
Prometheus UI:

Grafana UI:
Login into grafana dashboard using default username and password:
Username: admin
Password: prom-operator
Once logged in, you can start monitoring your Kubernetes cluster using Grafana’s user-friendly interface. Grafana will provide you with insightful graphs and metrics for analysis and optimization.
Step 6:
Monitoring CPU, Memory, Disk, and Error Codes.
Before we dive into monitoring CPU, memory, disk, and error codes in a Kubernetes cluster using tools like Prometheus and Grafana, let's first understand the concept of Kubernetes monitoring and the architecture of Prometheus,and grafana features.
Kubernetes monitoring is a critical process that involves examining and reporting the health status of various components within a Kubernetes cluster. It helps track the utilization of cluster resources such as memory, CPU, and storage, providing valuable insights into the overall performance and availability of the cluster.

Kubernetes brings challenges in managing high availability, performance, and container deployment. Monitoring these components becomes crucial. Fortunately, Kubernetes provides metrics through CAdvisor, which collects CPU, memory, network, and disk usage. These metrics are then pushed to the Metric Server using kubelet APIs.
While Kubernetes simplifies containerized application management, it introduces additional layers and abstractions, leading to a complex monitoring landscape. However, we have a range of excellent open-source tools available today to assist us in this endeavor.
Prometheus Architecture

Prometheus Server is the main component of Prometheus responsible for monitoring.
It includes a Time Series Database for storing metric data such as CPU and memory usage.
A Data Retrieval Worker pulls data from applications, services, servers, etc., and pushes it into the database.
The Server API accepts queries for the stored data, allowing for data display in dashboards or web UIs.
Why use Prometheus for Kubernetes monitoring🤔🤔??
Prometheus has become the preferred choice for Kubernetes monitoring due to the following reasons:
📊 Multi-dimensional data model: Prometheus employs a flexible key-value pair data model, similar to Kubernetes labels, allowing precise and flexible time series data querying.
🌐 Accessible format and protocols: Prometheus metrics are published using a straightforward HTTP transport, making them easily accessible and human-readable with self-explanatory formats.
🔎 Service discovery: Prometheus server automates the process of scraping metrics from targets, eliminating the need for applications and services to produce data actively. It can automatically discover and scrape targets, which is ideal for dynamic Kubernetes workloads.
🔌 Modular and high availability: Prometheus is built with modular components that handle tasks like metric gathering, alerting, and visualization. These components are designed to support sharding and redundancy, ensuring high availability.
With these features, Prometheus simplifies Kubernetes monitoring, providing a scalable and flexible solution to capture and analyze metrics in containerized environments
How does Prometheus work with Kubernetes?

📊 Prometheus on Kubernetes monitors various targets, including Linux/Windows servers, applications, Apache servers, and databases. These are referred to as "Targets".
🔍 It collects metrics such as CPU usage, memory usage, request counts, and exceptions. These metrics are referred to as "Metrics".
🎯 Prometheus categorizes metrics into three types:
Counter: Tracks the number of occurrences of a specific event, such as exceptions or requests.
Gauge: Represents a metric that can fluctuate, providing current values for CPU usage, disk usage, etc.
Histogram: Monitors the duration or size of requests or any other required metric.
📡 Prometheus pulls metric data from targets via HTTP endpoints (/metrics). If a target doesn't expose this endpoint, exporters come into play. Exporters retrieve metrics from targets, convert them into Prometheus-readable format, and expose the /metrics endpoint.
🚨 Prometheus includes the Alert Manager, responsible for sending alerts via Slack, email, and other mediums in case of cluster failures or resource limitations.
💾 Data collected by Prometheus is stored in a local disk or can be connected to remote storage. However, traditional relational databases are not suitable due to Prometheus' custom time-series format.
🔍 Querying Prometheus data is done using PromQL. Visualization of Prometheus data can be achieved using tools like the Prometheus web UI and Grafana.
🔄 Unlike centralized collection platforms, Prometheus adopts a pull-based system, where multiple Prometheus instances retrieve data, making it ideal for microservices. However, Prometheus also supports a push mechanism for short-lived jobs.
With these features, Prometheus becomes an efficient and flexible monitoring solution for Kubernetes, enabling effective tracking and analysis of various metrics in your environment.
Grafana:

📊 Grafana, an open-source visualization and analytics software, is a powerful tool for visualizing and analyzing large amounts of data. It provides a highly customizable dashboard that enables us to study, monitor, and analyze data over time. It seamlessly connects with various data sources such as Prometheus, Graphite, InfluxDB, Elasticsearch, and more.
🎨 Features of Grafana:
📊 Dashboard: Grafana's dashboard is a standout feature, continuously evolving and well-equipped to make sense of complex data.
🚨 Alerts: It allows setting up and triggering alerts based on specific conditions or events.
🔄 Native Support: Grafana has native support for a wide range of databases, providing flexibility in data integration.
🛠️ Built-in Support: It offers built-in support for popular tools like Prometheus, InfluxDB, CloudWatch, Graphite, and Elasticsearch.
With its robust features and wide-ranging data source compatibility, Grafana empowers users to gain valuable insights from their data and effectively visualize metrics in a visually appealing and interactive manner.
Logging into the Prometheus UI and Viewing Cluster Metrics
After setting up Prometheus in your Kubernetes cluster, you can access the Prometheus UI to explore and visualize the collected metrics. Follow these steps to log into the Prometheus UI and view the metrics in your cluster:
Obtain the Prometheus UI URL: The URL for accessing the Prometheus UI is typically a load balancer URL provided during the setup process. It could be something like aa279757c327f44f6b87fe65d0c6a998-662275886....
Once logged in, navigate to the status section of the Prometheus UI.
In the status section, you will find valuable information about the health and availability of your Kubernetes cluster. It provides an overview of various metrics and targets being monitored.
Look for the "Targets" section, which displays the available targets and their current status. Each target represents a specific component or service in your cluster, such as nodes, containers, or applications.



By monitoring the status of your cluster and the availability of targets in the Prometheus UI, you can ensure that your Kubernetes environment is functioning optimally. This enables you to take proactive measures and troubleshoot any issues promptly, leading to better cluster performance and stability.
Logging into the Grafana UI
Once you have Prometheus set up and running in your Kubernetes cluster, you can log into the Grafana UI to visualize and analyze your metrics data. Here's how to access the Grafana UI:
Login into grafana dashboard using default username and password:
Username: admin
Password: prom-operator

After logging in, you will be greeted by the Grafana home page, where you can create and explore dashboards.
Grafana supports various data sources, including Prometheus, InfluxDB, Graphite, and more. To connect Grafana with Prometheus, you need to add Prometheus as a data source. Click on the "Configuration" icon (gear icon) on the left sidebar, select "Data Sources," and then click on the "Add data source" button. Choose "Prometheus" as the type and provide the necessary details such as the Prometheus URL.
Once the Prometheus data source is added, you can start creating custom dashboards to visualize your metrics. Grafana provides a user-friendly interface to create graphs, charts, and other visualizations based on your metrics data.

Exploring Dashboards in Grafana
Once you log into the Grafana UI, you can start exploring and managing your dashboards. Here's an overview of the dashboard section in Grafana:
Click on the "Dashboards" option in the left sidebar menu.
In the dashboards section, you will find different tabs, including "Dashboards," "Playlists," "Snapshots," and "Library panels."
The "Dashboards" tab is where you create and manage your dashboards to visualize your data. Here, you can search for existing dashboards using the search bar.
You can create a new dashboard by clicking on the "New" button. This allows you to create a blank dashboard or choose from available templates.

To import pre-built dashboards from Grafana Labs, follow these steps:
Log into the Grafana UI.
Click on "Dashboards" in the left sidebar.
Click on the "New" button to create a new dashboard.
In the dashboard editor, click on the "Import" button.
You will be prompted to provide a dashboard JSON or YAML file. To import a pre-built dashboard from Grafana Labs, you can search for available dashboards on the Grafana Labs website or community dashboards repositories.
Once you find a dashboard you want to import, copy the JSON or YAML code.
Return to the Grafana UI and paste the JSON or YAML code into the import field.
Click on the "Load" button to load the dashboard.
Review the imported dashboard and make any necessary adjustments or configurations.
Save the dashboard to make it available for viewing and editing.

To access Grafana Labs and explore pre-built dashboards, you can follow these steps:
Open a web browser and go to the following link: grafana.com/grafana/dashboards.
The link will take you to the Grafana Labs website's dashboards page. Here, you can find a wide range of pre-built dashboards contributed by the Grafana community and maintained by Grafana Labs.

By copying the ID of the desired dashboard from Grafana Labs and importing it into your Grafana UI, you can quickly utilize the pre-built dashboard for monitoring your desired metrics and systems. This saves you time and effort in creating dashboards from scratch and leverages the expertise of the Grafana community and Grafana Labs.

Once you have loaded the pre-built dashboard in Grafana, you can access and interact with it by clicking on the dashboard name in the Grafana UI. The dashboard will display various panels and visualizations, providing insights into the monitored metrics. You can explore the panels, customize time ranges, and use interactive features like zooming and filtering to analyze the data. Take advantage of clickable elements and drill-down capabilities if available. By accessing the imported dashboard in Grafana, you can gain valuable insights and make data-driven decisions for optimizing your Kubernetes cluster's performance.
Node Exporter Full

When viewing the "Node Exporter Full" dashboard, you can see metrics for the last 24 hours. The dashboard is connected to a specific datasource, such as Prometheus, and shows metrics related to CPU, memory, and disk usage.
Some specific metrics displayed on the dashboard include:
CPU Busy: 6.01%
Sys Load (5m avg): 7.00%
Sys Load (15m avg): 5%
RAM Used: 68%
SWAP Used: NaN (Not a Number)
Root FS Used: 10.5%
CPU Cores: 2
Uptime: 2.5 weeks
RootFS Total: 80 GiB
RAM Total: 4 GiB
SWAP Total: 0 B
Kubernetes / Compute Resources / Namespace (Pods)



In the "Kubernetes / Compute Resources / Namespace (Pods)" dashboard, you can find information about CPU, memory, and disk utilization for the specified namespace and pods. Here are some highlights from the dashboard:
CPU Utilization:
CPU Utilization (from requests): 20.4%
CPU Utilization (from limits): 20.4%
Memory Utilization:
Memory Utilization (from requests): 247%
Memory Utilization (from limits): 741%
CPU Usage:
- Displays the CPU usage of different pods over time.
CPU Quota:
- Shows the CPU usage, CPU requests, and CPU limits for each pod.
Memory Usage:
- Displays the memory usage of different pods over time.
Memory Quota:
- Shows the memory usage, memory requests, and memory limits for each pod.
Kubernetes Nodes

The "Kubernetes Nodes" dashboard allows you to monitor key metrics related to your Kubernetes nodes. It provides information on system load, memory usage, disk I/O, and disk space utilization. By tracking these metrics, you can ensure the optimal performance and health of your nodes.
Kubernetes / Kubelet

The "Kubernetes / Kubelet" dashboard allows you to monitor key metrics related to your Kubernetes kubelets. It provides information on the number of running kubelets, pods, containers, actual volume count, desired volume count, and config error count. By tracking these metrics, you can ensure the smooth operation and configuration of your Kubernetes cluster.
Node Exporter / Nodes


The "Node Exporter / Nodes" dashboard provides an overview of key metrics related to Kubernetes nodes. It includes information on CPU usage, load average, memory usage, disk I/O, disk space usage, network received, and network transmitted. By monitoring these metrics, you can gain insights into the performance and resource utilization of your Kubernetes nodes.
Node Exporter for Prometheus Dashboard based

Kubernetes Cluster (Prometheus)

The "Kubernetes Cluster (Prometheus)" dashboard provides an overview of the cluster health and deployment metrics. It includes information on deployment replicas, deployment replicas - up to date, deployment replicas - updated, and deployment replicas - unavailable. By monitoring these metrics, you can assess the health and availability of your Kubernetes cluster and deployments.
Setting Up Metrics Alerts in Prometheus and Grafana:
Define the metrics you want to monitor and set alerting rules in Prometheus using Prometheus Query Language (PromQL).
Configure alerting in Grafana:
Go to "Alerting" -> "Notification channels" to add a notification channel for alert notifications.

Go to your custom dashboard, click on a panel, and select "Edit".
In the panel settings, go to the "Alert" tab and create alert rules based on your metrics.
Configure notification channels for each alert rule.


The "Alertmanager / Overview" dashboard provides a comprehensive overview of the alerts and notification send rates for the past hour. It allows you to monitor critical events and the performance of alerting mechanisms in your system.
Metrics:
Alerts: This section displays the count of alerts triggered over time, allowing you to track the frequency of critical events.
Alerts receive rate: This graph shows the rate at which alerts are being received, indicating the intensity of alerts being triggered.
Notifications:
email: Notifications Send Rate: This graph illustrates the rate at which email notifications are being sent for alerts.
opsgenie: Notifications Send Rate: This graph shows the rate at which notifications are being sent to OpsGenie, a popular incident management platform.
pagerduty: Notifications Send Rate: This graph displays the rate at which notifications are being sent to PagerDuty, a leading incident response platform.
pushover: Notifications Send Rate: This graph depicts the rate at which notifications are being sent to Pushover, a service for push notifications to mobile devices.
By analyzing these metrics and notification rates, you can ensure that your alerting system is functioning correctly and efficiently. This dashboard allows you to stay on top of critical alerts and take timely actions to maintain the health and reliability of your infrastructure.
Setting up EFK Stack for Log Monitoring using manifest files 📚📝

What is EFK Stack?
EFK stands for Elasticsearch, Fluent bit, and Kibana\.**
Elasticsearch is a scalable and distributed search engine that is commonly used to store large amounts of log data. It is a NoSQL database. Its primary function is to store and retrieve logs from fluent bit.
Fluent Bit is a logging and metrics processor and forwarder that is extremely fast, lightweight, and highly scalable. Because of its performance-oriented design, it is simple to collect events from various sources and ship them to various destinations without complexity.
Kibana is a graphical user interface (GUI) tool for data visualization, querying, and dashboards. It is a query engine that lets you explore your log data through a web interface, create visualizations for event logs, and filter data to detect problems. Kibana is being used to query elasticsearch indexed data.
Deploying EFK (Elasticsearch, Fluentd, Kibana) Stack for Log Management
We will walk through the step-by-step deployment of the EFK stack, comprising Elasticsearch, Fluentd, and Kibana. The components will be set up as follows:
Elasticsearch: Deployed as a statefulset to store the log data.
Kibana: Deployed as a deployment and connected to the Elasticsearch service endpoint.
Fluent-bit: Deployed as a daemonset to collect container logs from each node and forward them to the Elasticsearch service endpoint.
Step 1: Clone Your GitHub Repository Begin by cloning your GitHub repository containing the EFK manifest files:
git clone https://github.com/vikranth18devops/botapp.git
Step 2: Navigate to the EFK Directory Move to the EFK directory in your repository to access the manifest files for deployment:
cd bot/kubernetes_manifest_yml_files/04-EFK-Log
ls -la

In the '04-EFK-Log' directory, you will find the necessary manifest files for deploying the EFK stack.
Step 3: Create EFK Deployment Apply the manifest files to create the EFK stack deployment:
kubectl apply -f .
Step 4: Verify Pod Status Check the status of the pods in the 'efklog' namespace:
kubectl get pods -n efklog

Step 5: Get Service Information Retrieve information about the services in the 'efklog' namespace:
kubectl get svc -n efklog

Step 6: Enable Kibana Security Ensure that port 5601 is enabled in the Kibana Load Balancer for secure access: (Note: Provide instructions specific to your environment for enabling port 5601)
Step 7: Access Kibana URL Open your web browser and access the Kibana URL to interact with the dashboard.
Step 8: Create Index Patterns Create index patterns in Kibana by selecting '*' and '@timestamp' to index the log data.
Step 9: Explore Logs in Kibana Now you can explore and analyze your logs through the user-friendly Kibana dashboard.


In this visualization, we can see log entries from the 'bot-app' container running in the 'default' namespace. The logs show requests made to the server, including details like HTTP status codes, request methods, user agents, and more. The logs are grouped and displayed based on timestamps, allowing us to analyze the activity within the specified time range.

This visualization shows log entries from the 'bot-56d5875c7f-htdks' pod. The logs indicate an error occurred at Jul 22, 2023 @ 00:51:46.944. The error message reveals that an attempt was made to access the path "/usr/share/nginx/html/_ignition/execute-solution," but it failed with an error (2: No such file or directory). The request originated from the client with IP address 192.168.6.18, targeting the server at the host "52.70.38.147:8080".

This JSON document contains a log entry from the 'bot-56d5875c7f-htdks' pod, showing an error occurred at Jul 21, 2023 @ 19:21:46. The error description is "open() "/usr/share/nginx/html/_ignition/execute-solution" failed (2: No such file or directory)". The log belongs to the 'stderr' stream.

This log data shows various HTTP requests and their responses at different timestamps on Jul 22, 2023. The log includes information like the HTTP method, URL, response status code, response time, and data size. The requests were made to Elasticsearch and API endpoints.
CONCLUSION
This blog covered the essential prerequisites and step-by-step instructions for setting up a comprehensive log monitoring and alerting system in Amazon EKS. We deployed a sample application to monitor, configured Prometheus and Grafana for metrics visualization, and implemented alerts to proactively address critical issues. Additionally, we enhanced our log monitoring with the EFK stack. By mastering these techniques, we can ensure the optimal performance and reliability of our Kubernetes applications.
Thank you for reading! I hope you found this guide helpful and informative. If you have any questions or need further assistance, feel free to reach out. Happy exploring, and may your DevOps and cloud journey be successful and rewarding! 🙏🌟🚀
Resources:
Prometheus Documentation - Official documentation for Prometheus monitoring system.
Grafana Documentation - Official documentation for Grafana visualization platform.
EFK Stack Documentation - Official documentation for the Elasticsearch, Fluentd, and Kibana (EFK) stack.